はじめに
僕は日記をNotionで書き溜めている。日記をNotionで書き溜めると便利なことがある。
複数あるメリットの一つに、「感情分析が手軽にできる」というのがある。 継続的に日記を書いていると感情分析をしたくなることはよくあると思う。
人生は親切なので、いきなり答えを突きつけて「あなたの人生は間違っていました」なんて言うことはしない。実際には中間発表があって、「このまま行くとまずいぞ、方針を変えろ」と教えてくれる。クリスマスを含めて、年末は毎年訪れる「人生の中間発表」のタイミングだ。だから今年の振り返りの一環として、書き溜めた今年の日記を感情分析したいと思った。
※感情分析(sentiment analysis)が何かについては以下のHagging Faceの記事をご覧ください。
Sentiment analysis is the automated process of tagging data according to their sentiment, such as positive, negative and neutral. Sentiment analysis allows companies to analyze data at scale, detect insights and automate processes.
Notion APIを使えば日記のデータを機械的に取得することができる。Google Colabを使えばお手軽にTransformerが実行できる。面白そうなので、勉強も兼ねて今年自分が書いた日記を感情分析してみることにした。
- 期間:2023-01-01 ~ 2023-12-29
- 使用言語:Python 3.9.0
利用モデル:jarvisx17/japanese-sentiment-analysis
やってみる
Notion APIを利用して日記のテキストデータをCSV形式で保存し、そのデータを使ってGoogle Colabで感情分析する。
Notionのデータベースから日記を取得する
日記自体は単純な構造で、プロパティは日付しかない。下記の画像は今月のとある日の日記である。
そのまま単純にljarvisx17/japanese-sentiment-analysisのpipelineにかけると以下のようになる。
from transformers import pipeline model_name = "jarvisx17/japanese-sentiment-analysis" sentiment_analysis = pipeline("sentiment-analysis", model=model_name) sentiment_analysis( """ 8時に起きる。8時に起きるとオフィスに10時くらいに着く計算になる。 今日は同窓会があったらしい。Twitterで知った。インスタで流れてきたが、思っていたのとはちょっと違った。 ユニクロにいく。ヒートテックのニットキャップ、手袋を買う。 Macでプログラミングしようと思ったら、ワインのせいでキーボードがダメになっていたのに気づく。多分Apple Care送りになる。今年の仕事納めは強制的なものになりそうだ。 """ ) # [[{'label': 'negative', 'score': 0.999277055263519}]]
アゴタ・クリストフの小説が好きで、日記には「事実だけ」を書くようにしている。だからネガティブになる。
Notion APIの都合上、ページの本文部分(children)を取得する処理は面倒だが、タイトルやプロパティを取得するのは簡単である。
コードは下記のようになった。通常の文を表すParagraph形式とリストを表すbulleted_list_item形式しか対応していないが、年末なので対応する気になれなかった。
from notion_client import Client from pprint import pprint import pandas as pd import time from datetime import datetime notion = Client(auth="SECRET") database_id = "DATABASE_ID" data = [] next_cursor = None count = 0 fuck_the_roop = False while fuck_the_roop is False: print(next_cursor) if next_cursor is None: response = notion.databases.query(database_id=database_id) else: response = notion.databases.query( database_id=database_id, start_cursor=next_cursor ) for page in response["results"]: print(len(data)) time.sleep(0.5) count += 1 page_id = page["id"] page_content = notion.pages.retrieve(page_id=page_id) date = page_content["properties"]["日付"]["date"]["start"] print(date) if datetime.strptime(date, "%Y-%m-%d") < datetime(2023, 1, 1): fuck_the_roop = True break page_title = page_content["properties"]["名前"]["title"][0]["plain_text"] content_text_list = [] children = notion.blocks.children.list(block_id=page_id) for child in children["results"]: if "paragraph" in child and child["paragraph"]["rich_text"]: content_text = child["paragraph"]["rich_text"][0]["plain_text"] elif ( "bulleted_list_item" in child and child["bulleted_list_item"]["rich_text"] ): bulled_item_text = child["bulleted_list_item"]["rich_text"][0][ "plain_text" ] content_text = f"- {bulled_item_text}" else: continue content_text_list.append(content_text) content = "\n".join(content_text_list) data.append( { "日付": date, "title": page_title, "content": content, } ) next_cursor = response["next_cursor"] df = pd.DataFrame(data) df.to_csv("sentiment_analysis.csv", index=False)
結果的に、カラムとして「日付」「タイトル」「本文」を持つCSVファイルが生成される。
Transformerにかける
こちらはGoogle Colabで実施する。
from transformers import pipeline model_name = "jarvisx17/japanese-sentiment-analysis" sentiment_analysis = pipeline("sentiment-analysis", model=model_name)
import pandas as pd from transformers import AutoTokenizer raw_data = pd.read_csv('sentiment_analysis.csv') tokenizer = AutoTokenizer.from_pretrained("jarvisx17/japanese-sentiment-analysis") def trim_text_to_max_tokens(text, max_length=500): # トークン化 tokens = tokenizer.encode(text, add_special_tokens=True) # 最初の max_length トークンを取得 if len(tokens) >= max_length: tokens = tokens[:max_length] # トークンからテキストへの変換 trimmed_text = tokenizer.decode(tokens, skip_special_tokens=True) return trimmed_text def sentiment_analysis_function(text): try: text = trim_text_to_max_tokens(text) scores = sentiment_analysis(text)[0] if scores["label"] == "positive": return {"positive": scores["score"], "negative": None} elif scores["label"] == "negative": return {"positive": None, "negative": scores["score"]} except: return {"positive": None, "negative": None} sentiment_results = raw_data['content'].apply(sentiment_analysis_function) sentiment_df = pd.DataFrame(sentiment_results.tolist()) combined_data = pd.concat([raw_data, sentiment_df], axis=1) combined_data.head()
結果
感情分析してみた結果を出す。
日記充足率
感情分析自体の結果ではないが、どの程度日記を書いているのかを考慮する必要がある。「日記充足率」を以下のように定義する
日記充足率=その月の日記の数 / 月の日数
月毎の日記充足率は以下のようになった。
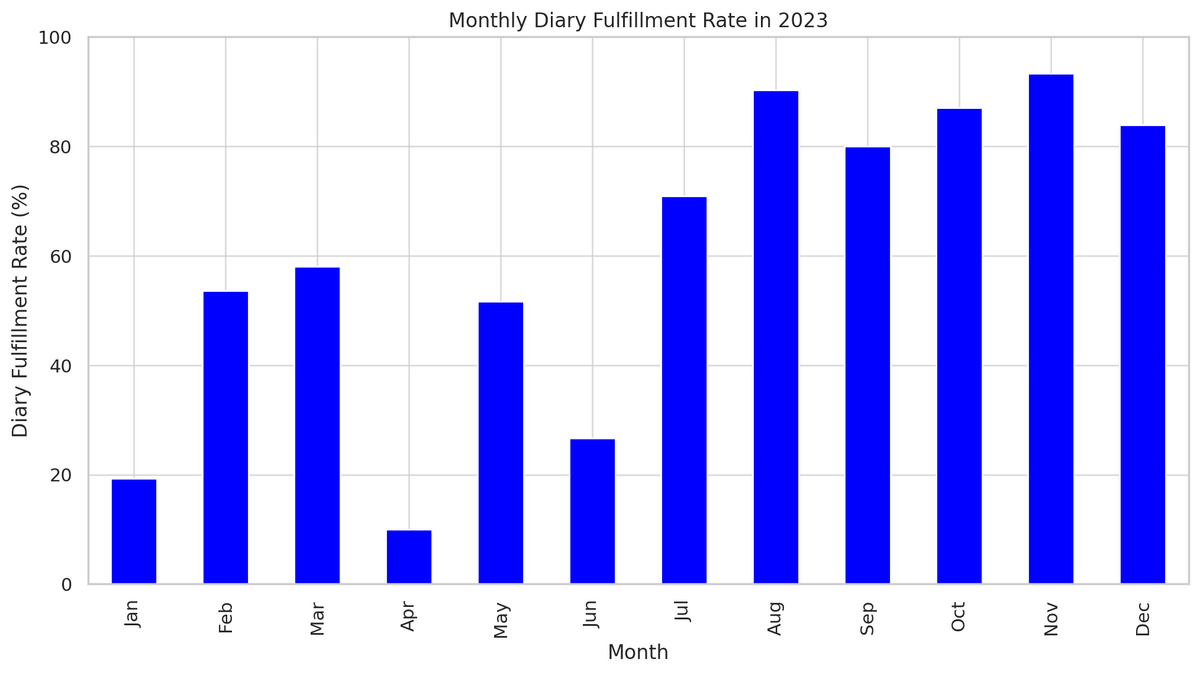
- 今年の前半(1月~6月)にかけては低い
- 後半(7月以降)には突然上がっている
これは、6月のある日突然「日記を書くことによってストレスが低減されているのではないか」という可能性に気付いたためである。日記を書く行為は排泄行為のようなもので、体に溜まったうんこを吐き出しているような感覚がある。
ちなみに、曜日単位での日記充足率は以下のようになった
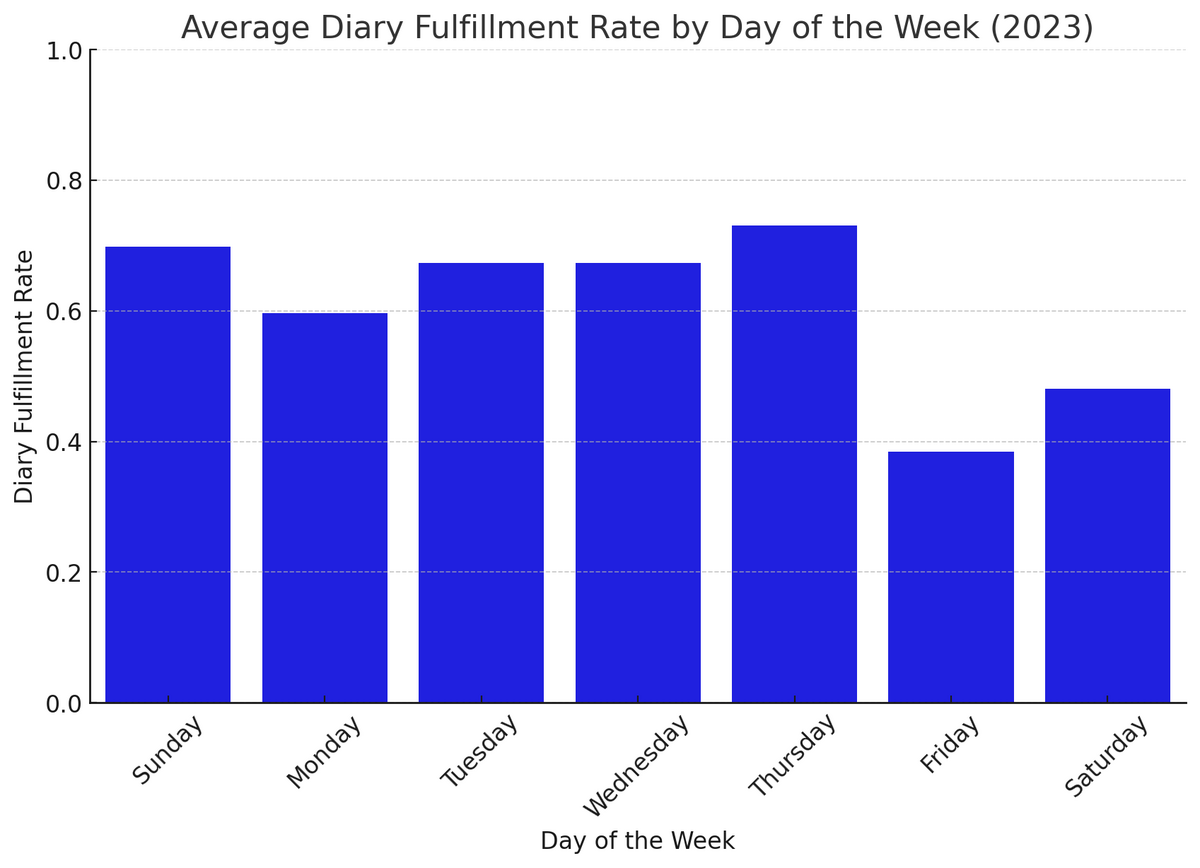
- 金・土が意外と少ない
金曜日は仕事から解放された喜びで酒を飲んで寝てしまうためである。土曜日に低い理由はよくわからない。
月毎のポジティブ・ネガティブ分布
次に、月毎の「ポジティブな日」と「ネガティブな日」の分布を示す。以下の定義で示される「Positivity Ratio」もプロットした。
Positivity Ratio = (ポジティブな日 - ネガティブな日) / 日記の合計数
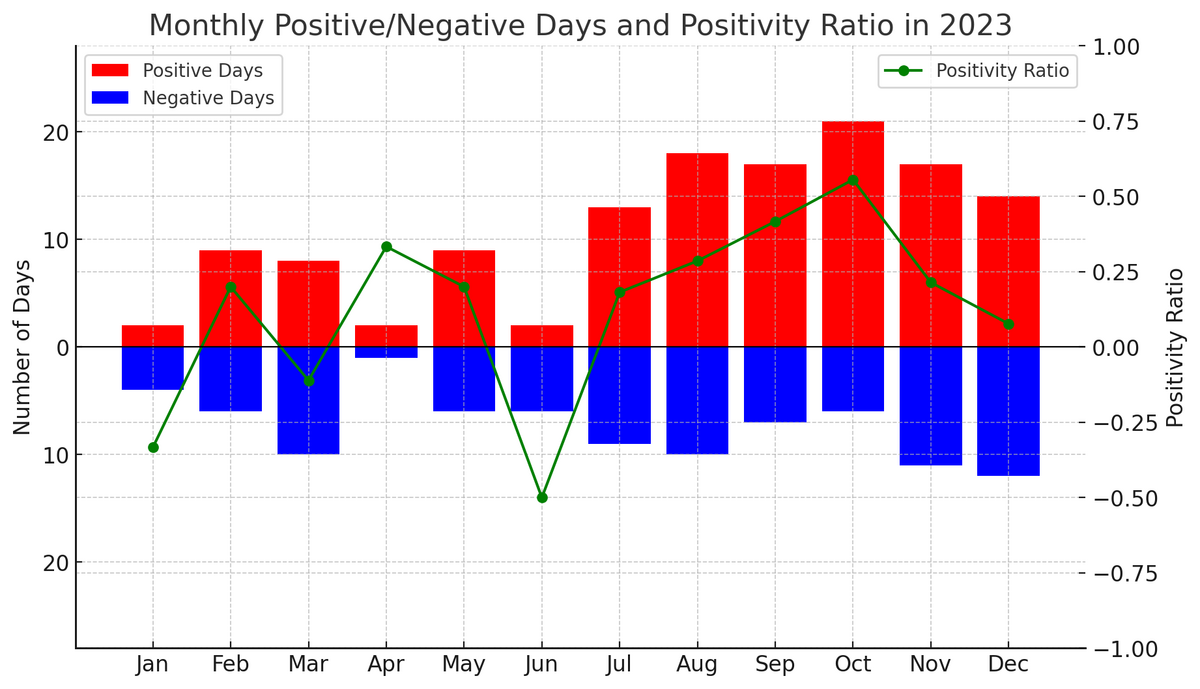
- 日記をまともに書いていなかった六月以前はネガティブ
- 日記をまともに書き始めた七月以降は比較的ポジティブ
これは、「日記を書くこと自体にストレスの低減作用がある」という仮説を補強している(ように見える)。ただの錯覚、交絡因子を見落としている可能性もある。
曜日単位でのポジティブ・ネガティブ分布は以下のようになった。
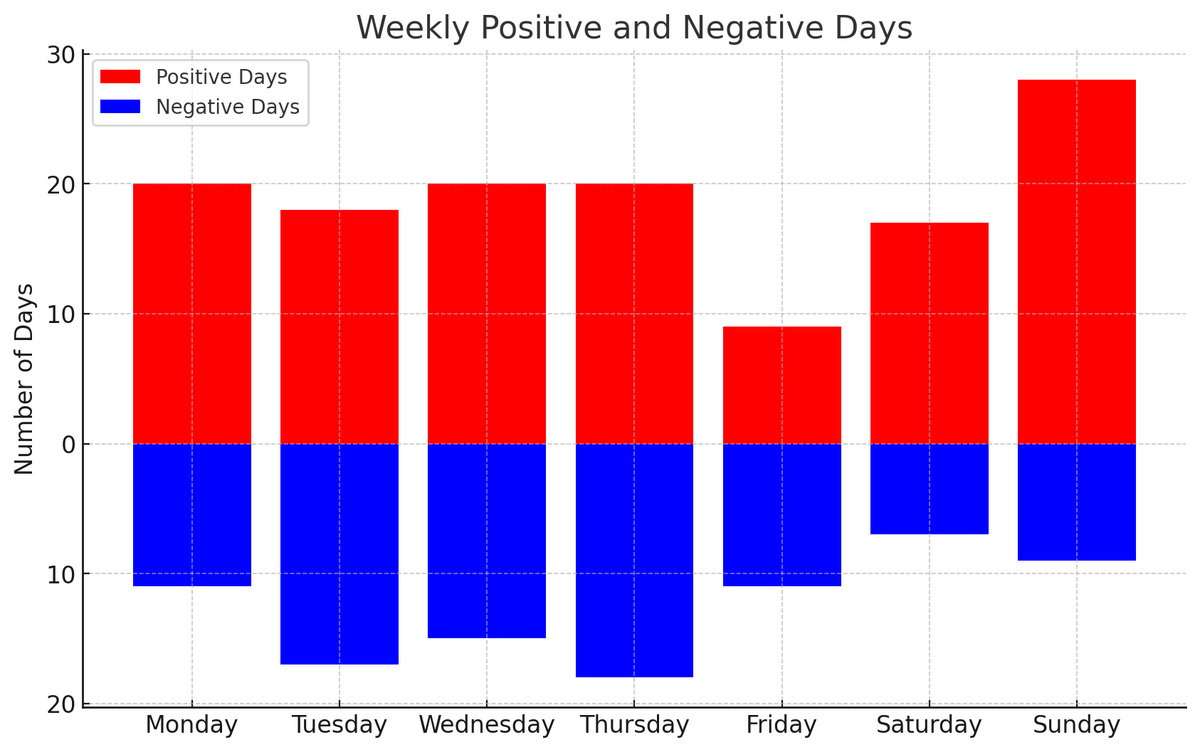
日曜日に思いの外リフレッシュしているのがわかる
おわりに
日記は排便だ。来年は毎日日記をつけようと思う