はじめに
※この記事は2023年のdbt Advent Calendarの19日目の記事です。
dbt-coreのオーケストレーションツールとしてDagster Cloudを導入してから4ヶ月ほど経った。ここで一度振り返り、普段当たり前のように使っているオーケストレーションツールの存在意義や技術選定のポイントに立ち返りつつ、Dagster Cloudを利用することのメリット・デメリットを書いていこうと思う。
想定読者層:
- dbtについてはある程度知っている方
- Airflowなどオーケストレーションツールをある程度触ったことがある方
目次:
オーケストレーションツールについて
データエンジニアは当たり前のようにAirflowなどのオーケストレーションツールを利用しているが、ここで改めてオーケストレーションを行うツールの存在意義を確認しておきたい。まずはOrchestrationの意味を振り返りつつ、オーケストレーションを実施するツールの技術選定のポイントを書き起こす。なぜこんなことを書くのかというと、Dagster Cloudを選定した理由と繋がってくるためである。
そもそもOrchestrationとは何か?
Joe ReisとMatt Housleyの著書Fundamentals of Data Engineering(pp120-122) において、Orchestrationは以下のように説明されている。
")
Orchestration is the process of coordinating many jobs to run as quickly and efficiently as possible on a scheduled cadence. (中略)An orchestration engine builds in metadata on job dependencies, generally in the form of a directed acyclic graph (DAG). The DAG can be run once or scheduled to run at a fixed interval of daily, weekly, every hour, every five minutes, etc. (中略)An orchestration system monitors jobs that it manages and kicks off new tasks as internal DAG dependencies are completed. It can also monitor external systems and tools to watch for data to arrive and criteria to be met. When certain conditions go out of bounds, the system also sets error conditions and sends alerts through email or other channels. (中略)Orchestration systems also build job history capabilities, visualization, and alerting. Advanced orchestration engines can backfill new DAGs or individual tasks as they are added to a DAG. They also support dependencies over a time range.
[筆者日本語訳]オーケストレーションとは、多くのジョブを計画的に、かつ効率的に素早く実行するプロセスです。具体的には、ジョブ間の依存関係をメタデータとして組み込んだ、指向性非巡回グラフ(DAG)に基づいてジョブを管理します。このDAGは、一度実行するか、毎日、毎週、毎時、5分ごとなど、固定された間隔でスケジュールされて実行されます。オーケストレーション・システムは、管理するジョブを監視し、内部DAGの依存関係が完了すると新しいタスクを開始します。また、外部システムやツールを監視し、データの到着や条件の達成を確認します。特定の条件が閾値に達すると、システムはエラー状態を認識し、メールなどのチャネルを通じてアラートを送信します。加えて、オーケストレーション・システムには、ジョブ履歴の機能、視覚化、アラート機能も組み込まれています。次世代のオーケストレーションエンジンは、新しいDAGや個々のタスクがDAGに追加された際のバックフィルをサポートするほか、時間範囲にわたる依存関係もサポートします。
改めて定義から振り返ると、オーケストレーションツールの役割の重要さがわかる。個々のタスクをノード、ノード同士の依存関係をエッジとみなせば、データ・パイプラインはグラフとなる。オーケストレーションツールはグラフを効率的に管理し、実行するための役割を果たす。オーケストレーションツールにより、データパイプラインの実行、モニタリング、トラブルシューティングの処理が抽象化され、ユーザーにとって管理可能なものとなる。その「管理のしやすさ」はデータ関連のプロジェクトの成功に不可欠な要素だ。なぜ不可欠なのかは後述する。
オーケストレーション・ツールが存在すると何が嬉しいのか?
すぅ〜(吸引)
オーケストレーションツールがあるのが当たり前だと思うなよ!!!!
すいません、取り乱しました。話を元に戻します。
オーケストレーションツールがあると何が嬉しいのかを考えてみるには、逆にオーケストレーションツールがない状態を考えてみればいい。例えば、コマンド dbt run を毎日深夜2時に実行するだけのEC2インスタンスがある場合を考えてみよう。
ジョブが成功した場合はいいだろう。失敗した場合はどうする?失敗した箇所を特定し、修正し、再度ジョブを実行する必要があるだろう。
あなたが朝9時に出勤してから1時間後、仕事をしていると、ダッシュボードの利用者から昨日分のデータが更新されていないと連絡が来た。失敗した箇所を特定するには、EC2のインスタンスにSSH接続してdbt.logファイルを閲覧し、失敗箇所を特定する必要がある。原因はSQLファイルのシンタックスエラーだったことがわかったとしよう。自分ではない誰かがファイルを修正して、シンタックスエラーを放置していたようだ。
あなたは.sqlファイルをvimで開き、修正して保存してから、再度dbt runを実行する。なお、ジョブ全体の実行には4時間かかるので、依存関係上最後に実行されるdaily_kpiテーブルが更新されるのは4時間後である。2時間後にある経営会議ではこのデータを利用するが、間に合わない。あなたはdbtに不慣れなので、dbtの最近のアップデートで失敗したモデルから実行することが可能であることは知らなかった。結果的に、事業上の価値は損なわれた。
上記は悲惨な例だが、オーケストレーションツールを導入すれば避けることはできた。オーケストレーションツールはジョブ実行やタスク管理に関する様々な動作を抽象化(abstruction)し、ジョブの実行がうまくいくようにユーザーを手助けしてくれる。具体的には、以下のような動作をユーザーにとって扱いやすいものにしてくれる。
- 失敗した箇所からのジョブのリトライ
- 複数ジョブの管理
- タスク*1間の調整・実行
- 各タスクの並行実行、依存関係処理
- 失敗した場合の通知
オーケストレーション・ツールの技術選定のポイント
改めて考えてみると、オーケストレーションツールはなくてはならないことがわかるだろう。しかし、オーケストレーションツールといってもいろいろある。 技術選定をするためには、いくつかのポイントを押さえる必要がある。先述のFundamentals of Data Engineeringで提唱された考えを踏襲しつつ、オーケストレーションツールに特化する形でポイントを書き起こす。
1. 可能な限りサーバーレスにする
以下の画像はAirflowのアーキテクチャだ。かなり簡潔に書いてあるが、コアとなるスケジューラやワーカー、Webサーバーなど、さまざまな要素が登場していることがわかる。
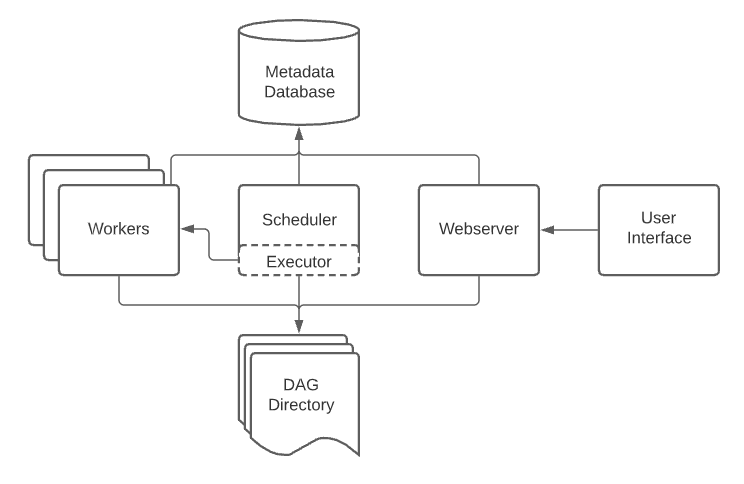
これをサーバーレスではない形態で運用するには労力がかかる。本来であれば、その労力はデータを用いた課題解決に使われるべき労力であり、サーバー管理のために使われるべきものではない。労力は有限であり、可能な限りビジネス上の価値に繋がるような労力の使い方をするべきだ。であるならば、なるべくサーバー管理に労力がかからないように運用するため、可能な限りサーバーレスなサービスを使った方が良いだろう。例えば、AWSにはMWAA (Managed Workflow for Apache Airflow), GCPにはCloud ComposerというマネージドAirflowのサービスがある。
なお、データ分析基盤がある程度大きくなれば、マネージドではない運用をしてもペイするようにはなるだろう。残念ながら、我々のチームの基盤は現状その規模には至っていない。
2. 他のツールとのInteroperatorbilityを担保する
interoperability : the ability of computer systems or software to exchange and make use of information. "interoperability between devices made by different manufacturers" (Oxford Languages)
Interoperatorbilityは日本語に訳せば「相互運用性」と呼ぶもので、オーケストレーションツールを選定する文脈では「技術同士の組み合わせの良さ」を意味する。Modern Data Stackというくらいなので、PaaS系のサービスを除き、モダンなデータ基盤を構成する技術は「組み合わせて」使うことが想定されている。この組み合わせがうまくいかないと、技術の持っているポテンシャルを最大限に引き出すことはできない。
つまり、「何を」オーケストレーションするのかに応じて、適切な技術選定は変わるということだ。例を挙げるよう。dbtのジョブをオーケストレーションするのと、Amazon AthenaのSQL文をオーケストレーションするのとでは、最適解が異なる。Airflowは現状最もdominantなオーケストレーションツールであるため、充実したエコシステムがある。そのため、Amazon AthenaのSQL文をオーケストレーションするのに最適なライブラリ(オペレータ)が存在している。Dagsterに同じものは存在しない。
dbtを理想的な形で(つまり、各モデルをタスクとして扱えるような形で)扱える形態は、自分の知る限りでは以下の4つしかない。
① dbt Cloud
② Airflow + BashOperator (個々のモデルに対してdbt run --selectをかけていくイメージ)
③ Dagster
④ Airflow + Cosmos(Astronomer社が開発したライブラリ)
他にも、DWHとして何を利用しているのか、クラウド環境として何を利用しているのか、あるいはそもそもクラウドを利用できる状態にあるのかなどに応じて、適切な技術選定は変わってくる。実務上、なんらかの制約条件が決まっている場合がほとんどだろう。オーケストレーションツールを適切に選定するには、他の技術との相互運用性を考慮する必要がある。
3. 開発のしやすさを確保する
開発者体験は、オーケストレーションツールの文脈でも重要である。ブランチ戦略やテストのしやすさ、デプロイのしやすさなど、開発時に考慮するべきことは多い。
- Jobに変更を加える場合、どのようなブランチ戦略になるのか。git-flowなのか、GitHub-flowなのか?
- ローカルでの開発が可能なのか
本番環境に変更を加えるまでのプロセスにおいて、最も制約が大きいのはオーケストレーションツールである。例えば、AirflowのAWS版マネージド環境であるMWAAは開発環境の立ち上げに30分程度かかることを考慮する必要がある。一方Dagster Cloudでは「ブランチデプロイ」機能が存在しているため、綺麗なGitHub-flowを描くことが可能だ。詳しくは後述する。
なお、開発のしやすさにはエンジニア組織の規模なども考慮に入れる必要がある。例えば、一人エンジニアなのにgit-flowを導入するようなことはやめよう。死ぬほど苦労する。
4. 運用のしやすさを確保する
運用のしやすさについて考えるためには、オーケストレーションが成功した時ではなく失敗した時をイメージするといい。
- 失敗したかどうかを知る手段は何か。自分から情報をとりにいかないといけない(プル型)なのか、自動でSlackなどに通知される(プッシュ型)なのか。プッシュ型の方が気づきやすい。ではその実装はどのようにやればいいのか?
- エラーログを見るにはどうすればいいか?Slackに直接吐き出すことはできるか?
- dbtをオーケストレーションする場合について。特定のモデルで処理が失敗した場合、全てをやり直す必要があるのか。特定のモデルの下流モデルのみをやり直す動作が可能なのか?
- 仮に全てをやり直すしかない場合、長い時間がかかってしまう。その時間は許容可能なのか?
- 一定の期間にわたってモデルを再実行すること(バックフィル)が可能なのかどうか。インクリメンタルなモデルの運用に耐えられるか?
余談だが、一昔前のStep Functionsは凄くて、ワークフローが一度失敗すると全部やり直す必要があった。最近修正されたようで何よりだが、もう使っていないのが残念である。
以上、オーケストレーションの定義から立ち返り、オーケストレーションツールの技術選定のポイントを見てきた。これらのポイントを踏まえてdagster Cloudを選定したわけだが、実際のところなぜその決定をしたのか、結果的にどのような価値をもたらしたか、デメリットは何かを次に見ていこうと思う。
Dagster Cloudでdbtを運用するメリット
まずはメリットから見ていこう。
1. サーバーレスな環境構築が可能
Dagster CloudのServerless Deploymentでは、サーバーレスな実行環境を構築することが可能である
サーバーレス環境にすることで、サーバーの保守・運用のコストを浮かし、浮いた労力をデータによる価値創出に向けることができる。ちなみに、実際はECSのタスクが動いているっぽい。なお、スケジューラーとWebUIのみDagster Cloud上で管理し、タスクの実行部分はユーザーが管理するHybridのデプロイ方式を選ぶこともできる。ただし、サーバーレスな実行環境自体はMWAAやCloud Composerでも提供可能なものであり、Dagster Cloud特有のメリットではない。
2. Pythonコードで書ければなんでもできる柔軟さがある
Pythonコードのdef文の中でassetとして定義できればなんでもいいので、事実上ほぼなんでもできる柔軟さを併せ持つ。当然うまく動作するのかどうか検証することが必要になってくるが、その場合は後述のブランチデプロイ機能を利用すればいい。これもサーバーレスな環境構築と同様、Airflowなどの別のオーケストレーションツールでもできることであるため、Dagster Cloud特有のメリットではない。
3. 強力な開発者体験:ローカル開発とブランチデプロイ環境構築
Dagsterが他のオーケストレーションツールと比べて際立っているのは、開発者体験を重視する点である。開発者体験の良さは、ローカル開発時とクラウド上でのテスト時に現れる。
dagsterはローカルでの開発性に優れており、VSCodeなどでコードを書きながらローカルで動作検証をすることが可能である。
また、パッケージの依存関係やクラウド上の権限管理が原因で、ローカル上でうまくできてもクラウド上でうまくいかない場合も想定されるだろう。可能な限り本番環境に近い環境で想定通りに動作するか否かは「ブランチデプロイ」機能を利用すれば検証可能である。
- 簡単にいうと、プルリクエストを提出したら、そのPRのコードの内容を反映したクラウド環境が作られ、テスト実行が可能であるということ
- GitHub Actionsで
profiles.ymlのdatabaseやschemaの値を動的に書き換える処理を挟めば、強力なテスト環境が得られる
ローカルでの開発環境とクラウド上でのテスト環境を組み合わせれば、シンプルなGitHub-flowを実現することができる。昔からKeep it simple, stupidと言われるように、開発フローは可能な限りシンプルなのが望ましい。
4. UIがイケてる
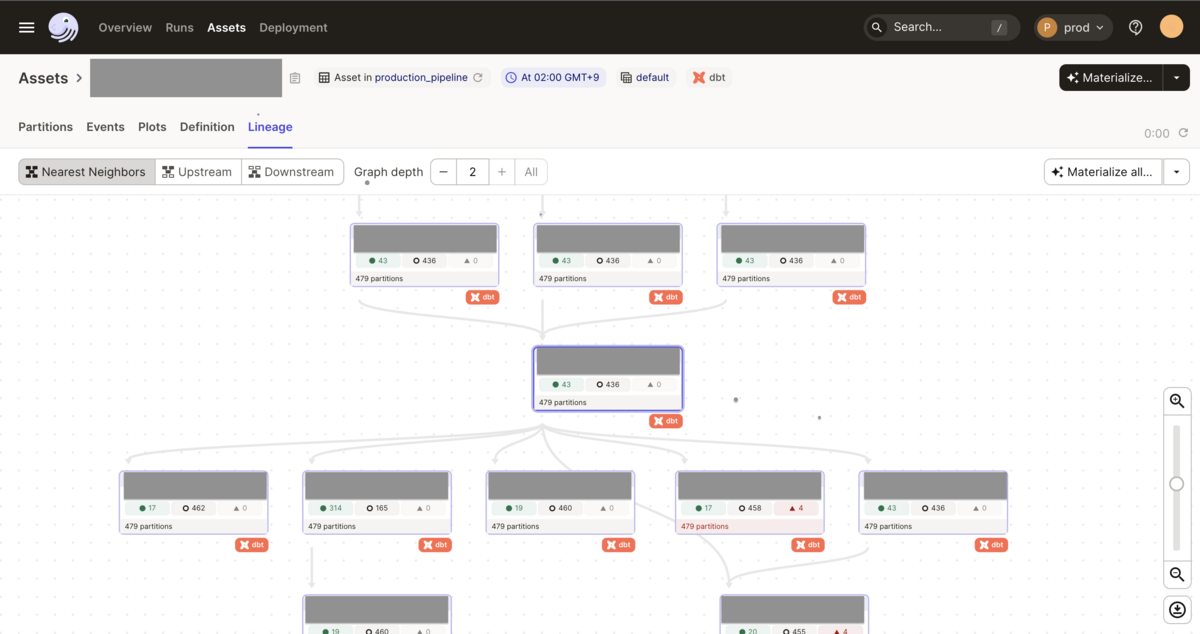
リネージュなどが見やすい。以下の画像は実際の画面だが、特定のモデルの下流のみ、あるいは上流のみに絞って閲覧することも可能である。なお、Web UIに関しては将来的に変わるかもしれない。
5. dbt Cloudと比較して、オーケストレーションの機能が充実している
まず、dbt Cloudはオーケストレーションツールではないので、オーケストレーションツールにあって欲しい機能を期待してはいけない。将来的に機能が拡充する可能性もあるだろうし、良い・悪いの話ではなく、そういうツールなのだからしょうがない。
一方、Dagster Cloudはモデルごとにかかった時間や、ジョブ全体の実行時間を継続的に監視し、個別に実行時間がかかっているモデルや全体の傾向を把握することが可能であり、予算管理やボトルネックの特定に役にたつ。
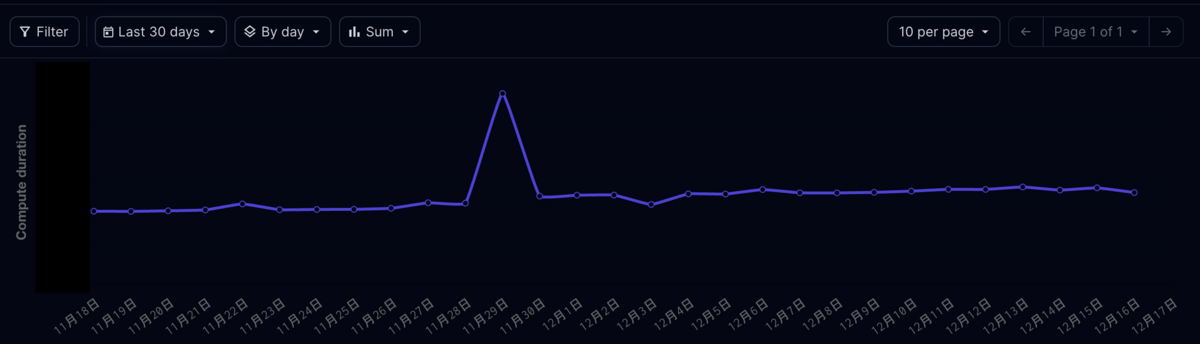
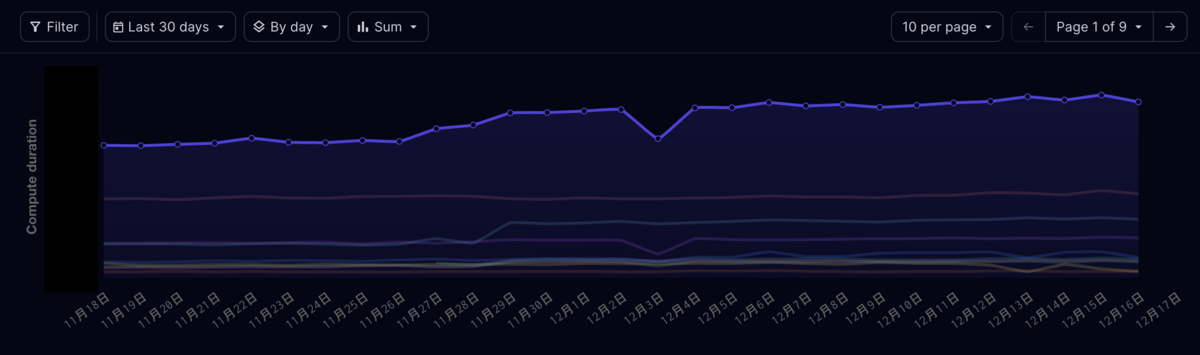
失敗したモデルのみ、あるいは特定のモデルの上流・下流のみを選択して実行することも可能であり、一定期間におけるバックフィルも可能である。
メリットのまとめ
Dagster Cloudのメリットは比較対象によって異なる、というのが結論である。
対サーバーレスAirflowの場合、開発者体験の良さがメリットになるだろう。また、バックフィルの機能はAirflowにはない(あってる?)ため、その機能差分もDagster Cloud特有のメリットになる。
対dbt Cloudの場合、オーケストレーションツールとしての機能の充実性がメリットになるだろう。また、Pythonであれば何でもできてしまう柔軟さや、UIのユーザービリティの高さも特有のメリットとなるだろう。
デメリット
メリットがあれば当然デメリットもある。一言で言えば、導入のハードルが高いことである。導入のハードルの高さを要素分解してみよう。
1. 学習の難易度が高い
dbt Cloudと比較した場合でいえば、学習の難易度が比較的高い。"asset"など、Dagsterには独特な概念が登場するため、Airflowなどの既存のオーケストレーションツールになれたエンジニアでも習得は簡単ではない。 運用を開始してから4ヶ月ほど経っているが、正直にいうとまだ「なんかエラー出てるけどうまくいかんな」という時はある。筆者の習熟度が低いだけかもしれない。
ただし、学習コストの高さは公式もわかっているようで、学習コンテンツはしっかり用意してある。
また、学習の難易度の高さは開発のしやすさで補うこと自体は可能である。
2. 導入社数が少ないので知見が溜まっていない
少なくとも日本では現状の導入社数は少ないため、現段階(2023年度の年末)での導入はある程度チャレンジングになることを認識する必要がある。具体的には、実装がうまくいかない時、Pythonのライブラリを読み解いてなんとかするような場面が結構あるため、それができるレベルのエンジニアが必要になる。この実務は「データ分析でPython触ってました!」くらいのPython習熟度だと厳しいかもしれない。
なお、dbt Cloud限定の機能は当然使えない。dbt-coreとdbt Cloudの機能差分を検討し、それでも大丈夫だと判断できる場合に利用すると良いと思う。
おわりに
書き終わった後に気づいたが、これではdagster Advent Calendarになってしまう...再掲するが、この記事は2023年のdbt Advent Calendarの19日目の記事です。
結論何がおすすめかというのは、データの利活用の度合いや事業のフェーズ、チームメンバーのスキルによって異なる。なので、ご利用は計画的にしましょう。
余談ではありますが、dbtがTerraform的なライセンスになったらどうしようかな〜と考えることはある。その時はその時か.....